简介
为促进中文领域的知识图谱构建和方便用户使用,DeepKE提供了预训练好的支持cnSchema的特别版DeepKE-cnSchema,支持开箱即用的中文实体抽取和关系抽取等任务,可抽取50种关系类型和28种实体类型,其中实体类型包含了通用的人物、地点、城市、机构等类型,关系类型包括了常见的祖籍、出生地、国籍、朝代等类型。
模型使用说明
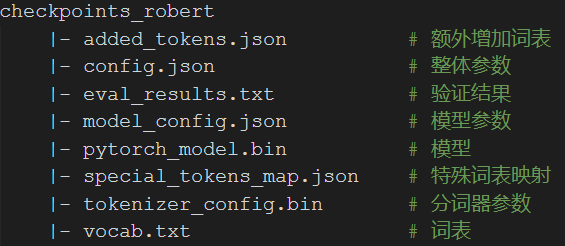
实体识别模型中,以Pytorch版DeepKE(NER), RoBERTa-wwm-ext, Chinese为例,下载后对zip文件进行解压可得到左图文件结构。
PyTorch版本则包含pytorch_model.bin, config.json, vocab.txt文件。
关系抽取模型中,以Pytorch版DeepKE(RE), RoBERTa-wwm-ext, Chinese为例,下载后为.pth文件,是可直接使用的模型。
中文基线效果
DeepKE基于chinese-roberta-wwm-ext和chinese-bert-wwm进行微调得到DeepKE-cnSchema(NER)和DeepKE-cnSchema(RE)模型。模型所使用的超参数均为预定义的参数,在测试数据集上效果如左图所示。
支持Schema类型
DeepKE(cnSchema) 特别版为支持中文领域知识图谱构建推出的开箱即用知识抽取模型。cnSchema是面向中文信息处理,利用先进的知识图谱、自然语言处理和机器学习技术,融合结构化与文本数据,支持快速领域知识建模,支持跨数据源、跨领域、跨语言的开放数据自动化处理,为智能机器人、语义搜索、智能计算等新兴应用市场提供schema层面的支持与服务。
目前,DeepKE(cnSchema) 支持的Schema类型如下所示
实体Schema
| 序号 | 实体类型 | 序号 | 实体类型 | 序号 | 实体类型 | 序号 | 实体类型 |
|---|---|---|---|---|---|---|---|
| 1 | cns:人物 | 2 | cns:影视作品 | 3 | cns:目 | 4 | cns:生物 |
| 5 | cns:Number | 6 | cns:Date | 7 | cns:国家 | 8 | cns:网站 |
| 9 | cns:网络小说 | 10 | cns:图书作品 | 11 | cns:歌曲 | 12 | cns:地点 |
| 13 | cns:气候 | 14 | cns:行政区 | 15 | cns:Text | 16 | cns:历史人物 |
| 17 | cns:学校 | 18 | cns:企业 | 19 | cns:出版社 | 20 | cns:书籍 |
| 21 | cns:音乐专辑 | 22 | cns:城市 | 23 | cns:经典 | 24 | cns:电视综艺 |
| 25 | cns:机构 | 26 | cns:作品 | 27 | cns:语言 | 28 | cns:学科专业 |
关系Schema
| 序号 | 头实体类型 | 尾实体类型 | 关系 | 序号 | 头实体类型 | 尾实体类型 | 关系 | 序号 | 头实体类型 | 尾实体类型 | 关系 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | cns:地点 | cns:人物 | cns:祖籍 | 2 | cns:人物 | cns:人物 | cns:父亲 | 3 | cns:地点 | cns:企业 | cns:总部地点 |
| 4 | cns:地点 | cns:人物 | cns:出生地 | 5 | cns:目 | cns:生物 | cns:目 | 6 | cns:Number | cns:行政区 | cns:面积 |
| 7 | cns:Text | cns:机构 | cns:简称 | 8 | cns:Date | cns:影视作品 | cns:上映时间 | 9 | cns:人物 | cns:人物 | cns:妻子 |
| 10 | cns:音乐专辑 | cns:歌曲 | cns:所属专辑 | 11 | cns:Number | cns:企业 | cns:注册资本 | 12 | cns:城市 | cns:国家 | cns:首都 |
| 13 | cns:人物 | cns:影视作品 | cns:导演 | 14 | cns:Text | cns:历史人物 | cns:字 | 15 | cns:Number | cns:人物 | cns:身高 |
| 16 | cns:企业 | cns:影视作品 | cns:出品公司 | 17 | cns:Number | cns:学科专业 | cns:修业年限 | 18 | cns:Date | cns:人物 | cns:出生日期 |
| 19 | cns:人物 | cns:影视作品 | cns:制片人 | 20 | cns:人物 | cns:人物 | cns:母亲 | 21 | cns:人物 | cns:影视作品 | cns:编辑 |
| 22 | cns:国家 | cns:人物 | cns:国籍 | 23 | cns:人物 | cns:影视作品 | cns:编剧 | 24 | cns:网站 | cns:网站小说 | cns:连载网络 |
| 25 | cns:人物 | cns:人物 | cns:丈夫 | 26 | cns:Text | cns:历史人物 | cns:朝代 | 27 | cns:Text· | cns:人物 | cns:民族 |
| 28 | cns:Text | cns:历史人物 | cns:朝代 | 29 | cns:出版社 | cns:书籍 | cns:出版社 | 30 | cns:人物 | cns:电视综艺 | cns:主持人 |
| 31 | cns:Text | cns:学科专业 | cns:专业代码 | 32 | cns:人物 | cns:歌曲 | cns:歌手 | 33 | cns:人物 | cns:歌曲 | cns:作曲 |
| 34 | cns:人物 | cns:网络小说 | cns:主角 | 35 | cns:人物 | cns:企业 | cns:董事长 | 36 | cns:Date | cns:机构 | cns:成立时间 |
| 37 | cns:学校 | cns:人物 | cns:毕业院校 | 38 | cns:Number | cns:机构 | cns:占地面积 | 39 | cns:语言 | cns:国家 | cns:官方语言 |
| 40 | cns:Text | cns:行政区 | cns:邮政编码 | 41 | cns:Number | cns:行政区 | cns:人口数量 | 42 | cns:Date | cns:企业 | cns:成立日期 |
| 43 | cns:人物 | cns:图书作品 | cns:作者 | 44 | cns:Date | cns:企业 | cns:成立日期 | 45 | cns:人物 | cns:歌曲 | cns:作曲 |
| 46 | cns:气候 | cns:气候 | cns:行政区 | 47 | cns:人物 | cns:电视综艺 | cns:嘉宾 | 48 | cns:人物 | cns:影视作品 | cns:主演 |
| 49 | cns:作品 | cns:影视作品 | cns:改编自 | 50 | cns:人物 | cns:企业 | cns:创始人 |
模型快速使用
实体识别(NER)
用户可以直接下载模型进行使用,具体流程如下:
1. 将下载文件夹命名为checkpoints
2. 修改源码中的get_labels函数,返回的标签改为所给type.txt中所用到的标签
def get_labels(self):
return ['O', 'B-YAS', 'I-YAS', 'B-TOJ', 'I-TOJ', 'B-NGS', 'I-NGS',
'B-QCV', 'I-QCV', 'B-OKB', 'I-OKB', 'B-BQF', 'I-BQF', 'B-CAR',
'I-CAR', 'B-ZFM', 'I-ZFM', 'B-EMT', 'I-EMT', 'B-UER', 'I-UER',
'B-QEE', 'I-QEE', 'B-UFT', 'I-UFT', 'B-GJS', 'I-GJS', 'B-SVA',
'I-SVA', 'B-ANO', 'I-ANO', 'B-KEJ', 'I-KEJ', 'B-ZDI', 'I-ZDI',
'B-CAT', 'I-CAT', 'B-GCK', 'I-GCK', 'B-FQK', 'I-FQK', 'B-BAK',
'I-BAK', 'B-RET', 'I-RET', 'B-QZP', 'I-QZP', 'B-QAQ', 'I-QAQ',
'B-ZRE', 'I-ZRE', 'B-TDZ', 'I-TDZ', 'B-CVC', 'I-CVC', 'B-PMN',
'I-PMN', '[CLS]', '[SEP]']
3. 修改predict.yaml中的参数text为需要预测的文本
4. 进行预测,需要预测的文本及实体对通过终端输入给程序
python predict.py
使用训练好的模型,只需输入句子“《星空黑夜传奇》是连载于起点中文网的网络小说,作者是啤酒的罪孽”,运行 ``python predict.py``后可得到结果,结果显示“星空黑夜传奇”实体类型为“网络小说”,“起点中文网”实体类型为为“网站”,“啤酒的罪孽”实体类型为“人物。
修改predict.yaml中的参数text为需要预测的文本
text=“《星空黑夜传奇》是连载于起点中文网的网络小说,作者是啤酒的罪孽”
最终输出结果
NER句子:
《星空黑夜传奇》是连载于起点中文网的网络小说,作者是啤酒的罪孽
NER结果:
[('星','B-UER'),('空','I-UER'),('黑','I-UER'),('夜','I-UER'),('传','I-UER'),
('奇','I-UER'),('起','B-ZFM'),('点','I-ZFM'),('中','I-ZFM'),('文','I-ZFM')
('网','I-ZFM'),('啤','B-YAS'),('酒','I-YAS'),('的','I-YAS'),('罪','I-YAS'),
('孽','I-YAS')]
关系抽取(RE)
用户可以直接下载模型进行使用,具体流程如下:
1. 修改predict.yaml中的参数fp为下载文件的路径,embedding.yaml中num_relations为51 (关系个数)
2. 进行预测,需要预测的文本及实体对通过终端输入给程序
python predict.py
使用训练好的模型,运行 ``python predict.py``后,输入句子“歌曲《人生长路》出自刘德华国语专辑《男人的爱》,由李泉作词作曲,2001年出行发版”,给定实体对为“男人的爱”和“人生长路”,即可抽取出关系“所属专辑”。
将predict.py中的_get_predict_instance函数改成如下范例,即可修改文本进行预测
def _get_predict_instance(cfg):
flag = input('是否使用范例[y/n],退出请输入: exit .... ')
flag = flag.strip().lower()
if flag == 'y' or flag == 'yes':
sentence = '歌曲《人生长路》出自刘德华国语专辑《男人的爱》,由李泉作词作曲
2001年出行发版'
head = '男人的爱'
tail = '人生长路'
head_type = ''
tail_type = ''
elif flag == 'n' or flag == 'no':
sentence = input('请输入句子:')
head = input('请输入句中需要预测关系的头实体:')
head_type = input('请输入头实体类型(可以为空,按enter跳过):')
tail = input('请输入句中需要预测关系的尾实体:')
tail_type = input('请输入尾实体类型(可以为空,按enter跳过):')
elif flag == 'exit':
sys.exit(0)
else:
print('please input yes or no, or exit!')
_get_predict_instance()
instance = dict()
instance['sentence'] = sentence.strip()
instance['head'] = head.strip()
instance['tail'] = tail.strip()
if head_type.strip() == '' or tail_type.strip() == '':
cfg.replace_entity_with_type = False
instance['head_type'] = 'None'
instance['tail_type'] = 'None'
else:
instance['head_type'] = head_type.strip()
instance['tail_type'] = tail_type.strip()
return instance
最终输出结果
“男人的爱”和“人生长路”在句中关系为“所属专辑”,置信度为0.99
联合三元组抽取
用户可以先将上述模型下载至本地,然后使用example/triple中的代码进行三元组抽取。 如果单句中存在超过两个以上的实体数,可能在一些实体对中会存在预测不准确的问题,那是因为这些实体对并没有被加入训练集中进行训练,所以需要进一步判断,具体使用步骤如下:
1. 将conf文件夹中的predict.yaml中的text修改为预测文本,nerfp修改为NER模型文件夹地址,refp为RE模型地址
2. 进行预测
python predict.py
期间将输出各个中间步骤结果,以输入文本此外网易云平台还上架了一系列歌曲,其中包括田馥甄的《小幸运》等为例
2.1 输出经过NER模型后得到结果
[('田', 'B-YAS'), ('馥', 'I-YAS'), ('甄', 'I-YAS'), ('小', 'B-QEE'), ('幸', 'I-QEE'), ('运', 'I-QEE')]
2.2 输出进行处理后结果
{'田馥甄': '人物', '小幸运': '歌曲'}
2.3 输出经过RE模型后得到结果
"田馥甄" 和 "小幸运" 在句中关系为:"歌手",置信度为0.92。
2.4 输出jsonld格式化后结果
{
"@context": {
"歌手": "https://cnschema.openkg.cn/item/%E6%AD%8C%E6%89%8B/16693#viewPageContent"
},
"@id": "田馥甄",
"歌手": {
"@id": "小幸运"
}
}
自定义模型 (高级用户)
支持模型在自定义数据集上进行训练
实体识别(NER)
如果需要使用其他数据进行训练,步骤如下:
1. 下载自定义的数据集,将其放入命名为data的文件夹中
2. 将conf文件夹下train.yaml中的bert_model修改为指定模型,用户可以通过修改yaml文件选择不同的模型进行训练
3. 进行训练
python run.py
关系抽取(RE)
如果需要使用其他模型进行训练,步骤如下:
1. 下载自定义的数据集,将其重命名为data
2. 将conf文件夹下train.yaml中的model_name改为lm,lm.yaml中的lm_file修改为指定预训练模型,embedding.yaml中num_relations为关系的个数如51,用户可以通过修改yaml文件选择不同的模型进行训练
3. 进行训练
python run.py
FAQ
引用
如果本项目中的资源或技术对你的研究工作有所帮助,欢迎在论文中引用下述论文。
@article{zhang2022deepke,
title={DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population},
author={Zhang, Ningyu and Xu, Xin and Tao, Liankuan and Yu, Haiyang and Ye, Hongbin and Shuofei, Qiao and Xie, Xin and Chen, Xiang and Li, Zhoubo and Li, Lei and Liang, Xiaozhuan and others},
journal={arXiv preprint arXiv:2201.03335},
year={2022}
}
免责声明
该项目中的内容仅供技术研究参考,不作为任何结论性依据。使用者可以在许可证范围内任意使用该模型,但我们不对因使用该项目内容造成的直接或间接损失负责。
问题反馈
如有问题,请在GitHub Issue中提交。